.jpg)

Na początek trochę teorii i historii
Baza danych– zbiór danych zapisanych zgodnie z określonymi regułami. W węższym znaczeniu obejmuje dane cyfrowe gromadzone zgodnie z zasadami przyjętymi dla danego programu komputerowego specjalizowanego do gromadzenia i przetwarzania tych danych. Program taki (często pakiet programów) nazywany jest „system zarządzania bazą danych” (ang.database management system, DBMS).
Programy do obsługi bazy danych operują głównie na danych tekstowych i liczbowych, lecz większość współczesnych systemów umożliwia przechowywanie danych cyfrowych różnego typu: dane o nieokreślonej strukturze, grafika, muzyka, obiekty itp.
Pierwszy system zarządzania bazami danych został opracowany w latach sześćdziesiątych XX wieku. Pionierem był Charles Bachman. Wczesne opracowania Bachmana pokazywały, że jego celem było bardziej efektywne użycie nowych urządzeń bezpośredniego dostępu do składowanych danych, które wtedy zaczynały być dostępne. Jak dotąd, przetwarzanie danych było oparte na kartach dziurkowanych i taśmach magnetycznych. Oznaczało to szeregowy dostęp do danych, co pociągało za sobą użycie innych algorytmów niż dla dostępu swobodnego.
Powstały wtedy dwa kluczowe: modele danych: sieciowy, opracowany przez CODASYL na bazie idei Bachmana i (być może niezależnie) hierarchiczny, użyty w systemie opracowanym przez North American Rockwell i później adoptowany przez IBM jako kamień milowy dla IMS. W tym czasie, oprócz CODASYL IDMS i IMS, powstały także inne bazy danych. Dwie warte wzmianki to: PICK i MUMPS, które były opracowane wcześniej jako systemy operacyjne z wbudowanymi bazami danych, a potem językami programowania i bazami danych do stosowania w systemach opieki zdrowotnej.
W 1970 E. F. Codd zaproponował relacyjny model danych. Krytykował on istniejące modele danych za mieszanie abstrakcyjnego opisu struktury informacyjnej z opisami mechanizmów fizycznego dostępu. Jednak przez dłuższy czas model relacyjny pozostawał tylko w sferze rozważań akademickich. Podczas gdy produkty CODASYL (IDMS) i IBM (IMS) były uważane za praktyczne rozwiązania wymagające tylko dostępnych wówczas technologii, to model relacyjny musiał poczekać na odpowiedni poziom rozwoju oprogramowania i sprzętu. Jednym z pierwszych implementacji modelu relacyjnego były: Ingres Michaela Stonebrakera z Berkeley i System R z IBM. Oba były prototypami badawczymi, ogłoszonymi w roku 1976. Pierwsze komercyjne rozwiązania, Oracle i DB2 nie były dostępne aż do roku około 1980. Natomiast pierwszym udanym produktem tego typu dla mikrokomputerów był dBASE dla systemów operacyjnych CP/M i PC/DOS/MS/DOS.
Pierwsze lata XXI wieku są okresem dużego zainteresowania bazami danych XML. W tym czasie, podobnie jak to było w przypadku obiektowych baz danych, powstało sporo nowych firm-producentów tych baz, ale kluczowe ich elementy są wbudowywane także w istniejące relacyjne bazy danych. Celem baz danych XML jest usunięcie tradycyjnego podziału na dokumenty i dane, pozwalając na trzymanie wszystkich zasobów informacyjnych organizacji w jednym miejscu, obojętnie czy te dane są wysoce ustrukturalizowane czy nie.
Z czego skłąda się baza danych?
Baza danych jest złożona z różnych elementów. Najważniejszymi z nich jest rekord podzielony na kilka pól, w których są przechowywane informacje poszczególnych kategorii. Na przykład w książce adresowej każdy rekord to zbiór informacji na temat jednej osoby. Składa się on z kilku pól przechowujących takie informacje, jak: imię, nazwisko, adres, numer telefonu itp. W każdym polu zapisywane są dane oddzielonej kategorii. Dzięki temu komputerowe bazy danych umożliwiają szybkie sortowanie rekordów według poszczególnych kategorii lub wyszukiwanie informacji w obrębie tylko wybranych pól. Wiele systemów zarządzania bazami danych oferuje możliwość tworzenia masek wprowadzania danych, które służą do bardziej wygodnego wprowadzenia nowych informacji. Naturalnie można z nich zrezygnować i wpisywać dane do bazy wyświetlanej w postaci tabelarycznej.
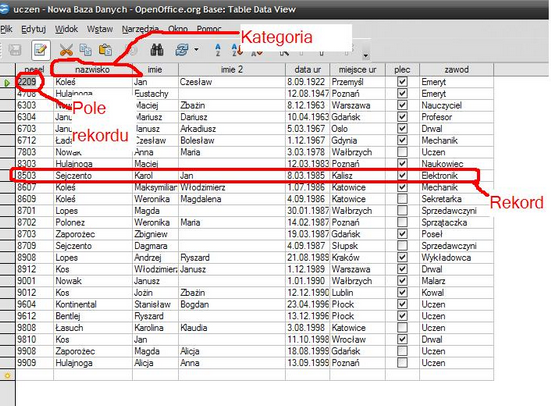 ]
]
Rodzaje baz danych
Bazy danych można podzielić według struktur organizacji danych, których używają:
Bazy proste:
- bazy kartotekowe
- hierarchiczne bazy danych
Bazy złożone:
- bazy relacyjne
- bazy obiektowe
- bazy relacyjno-obiektowe
- strumieniowe bazy danych
- temporalne bazy danych
Bazy kartotekowe
W bazach kartotekowych każda tablica danych jest samodzielnym dokumentem i nie może współpracować z innymi tablicami. Z baz tego typu korzystają liczne programy typu: książka telefoniczna, książka kucharska, spisy książek, kaset i inne. Wspólną cechą tych baz jest ich zastosowanie w jednym wybranym celu.
Sieciowe bazy danych
Model historyczny, pozwalał tylko na związki binarne; wiele do jeden.
Hierarchiczne bazy danych
Przykładem hierarchicznej bazy danych jest opracowana przez IBM baza IMS (ang.Information Management System).
Bazy relacyjne
W bazach relacyjnych wiele tablic danych może współpracować ze sobą (są między sobą powiązane). Bazy relacyjne posiadają wewnętrzne języki programowania, wykorzystujące zwykle SQL (strukturalny język zapytań używany do tworzenia, modyfikowania baz danych oraz do umieszczania i pobierania danych z baz danych) do operowania na danych, za pomocą których tworzone są zaawansowane funkcje obsługi danych. Relacyjne bazy danych (jak również przeznaczony dla nich standard SQL) oparte są na kilku prostych zasadach:
1. Wszystkie wartości danych oparte są na prostych typach danych.
2. Wszystkie dane w bazie relacyjnej przedstawiane są w formie dwuwymiarowych tabel (w matematycznym żargonie noszących nazwę „relacji”). Każda tabela zawiera zero lub więcej wierszy (w tymże żargonie – „krotki”) i jedną lub więcej kolumn („atrybutów”). Na każdy wiersz składają się jednakowo ułożone kolumny wypełnione wartościami, które z kolei w każdym wierszu mogą być inne.
3. Po wprowadzeniu danych do bazy, możliwe jest porównywanie wartości z różnych kolumn, zazwyczaj również z różnych tabel, i scalanie wierszy, gdy pochodzące z nich wartości są zgodne. Umożliwia to wiązanie danych i wykonywanie stosunkowo złożonych operacji w granicach całej bazy danych.
4. Wszystkie operacje wykonywane są w oparciu o algebrę relacji, bez względu na położenie wiersza tabeli. Nie można więc zapytać o wiersze, gdzie (x=3) bez wiersza pierwszego, trzeciego i piątego. Wiersze w relacyjnej bazie danych przechowywane są w porządku zupełnie dowolnym – nie musi on odzwierciedlać ani kolejności ich wprowadzania, ani kolejności ich przechowywania.
5. Z braku możliwości identyfikacji wiersza przez jego pozycję pojawia się potrzeba obecności jednej lub więcej kolumn niepowtarzalnych w granicach całej tabeli, pozwalających odnaleźć konkretny wiersz. Kolumny te określa się jako „klucz podstawowy” (ang. primary key) tabeli.
Bazy obiektowe
W bazach obiektowych dane przechowywane są w strukturach obiektowych (zdefiniowanych jako klasy). Koncepcje akademickie dotyczące baz obiektowych były najbardziej popularne w latach 90. Współcześnie popularność tego tematu zmalała, choć prace badawcze nad nimi nadal trwają, a na rynku pojawiły się obiektowe SZBD (np. Versant, db4o, LoXiM). Prace nad obiektowymi bazami danych ponowiło międzynarodowe konsorcjum OMG.
Bazy relacyjno-obiektowe
Bazy relacyjno-obiektowe pozwalają na manipulowanie danymi jako zestawem obiektów, posiadają jednak bazę relacyjną jako wewnętrzny mechanizm przechowywania danych.
Temporalna baza danych
Temporalne baza danych jest odmianą bazy relacyjnej, w której każdy rekord posiada stempel czasowy, określający czas w jakim wartość jest prawdziwa. Posiada także operatory algebry relacyjnej, które pozwalają operować na danych temporalnych (wyciągać historię).
Strumieniowe bazy danych
Strumieniowa baza danych to baza danych, w której dane są przedstawione w postaci zbioru strumieni danych. System zarządzania taką bazą nazywany jest strumieniowym systemem zarządzania danymi (DSMS- ang. Data Stream Management System).
Większość strumieniowych baz danych w chwili obecnej (początek 2005 r.) znajduje się w fazach prototypowych i nie powstały dotychczas rozwiązania komercyjne.
Strumieniowe bazy danych z reguły implementują języki ciągłych zapytań opartych na SQL-u (istnieją jednak wyjątki od tej reguły - np. rozwiązania graficzne).
Jak sporządzić bazę danych w programie Open Office?
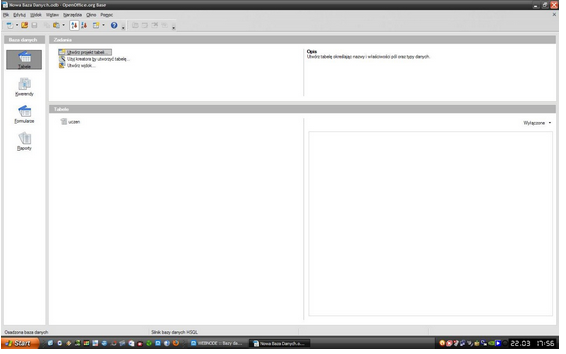
Najpierw wybieramy opcję "Tabela" i przechodząc przez kolejne kroki docieramy do okna, w którym możemy zaprojektować naszą bazę danych.
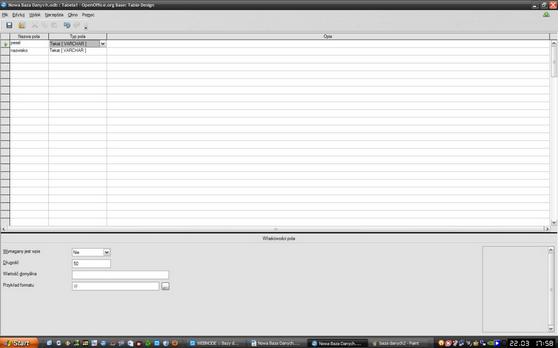
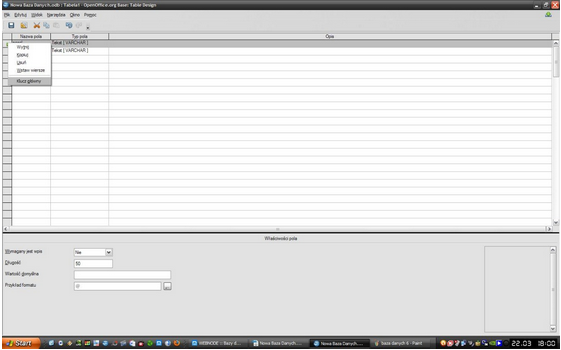
Na powyższym zdjęciu widzimy wcześniej wspomniane okno, w którym projektujemy tabelę, a dokładniej określamy kategorie, jakie ma zawierać oraz "Typ pola", gdzie wybieramy rodzaj informacji, jaką ma zawierać pole. Zostało to pokazane na poniższych zdjęciach.
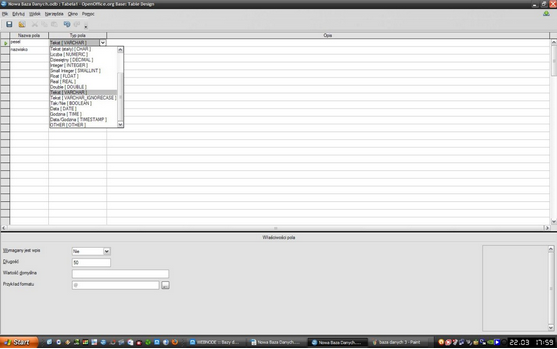
Istotnym momentem po określeniu poszczególnych kategorii jest wybór "Klucza głównego", na podstawie którego będą wyszukiwane dane informacje. Aby to zrobić należy nacisnąć prawym przyciskiem myszy na kratkę obok kategorii, którą chcemy oznaczyć.
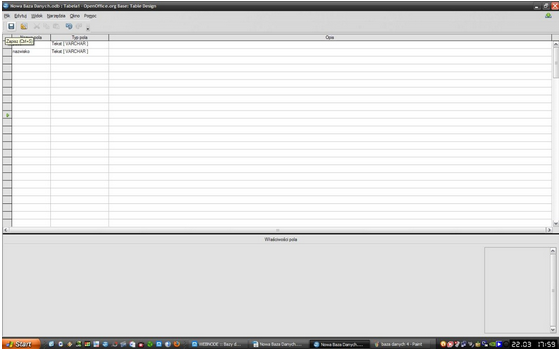
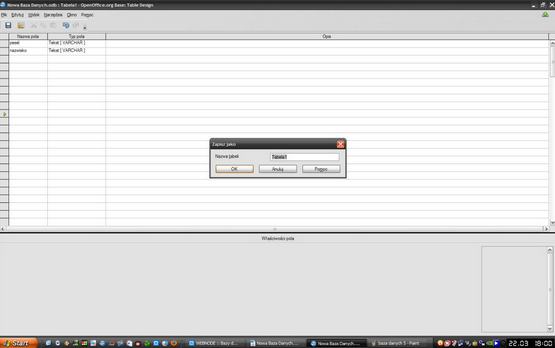
Po tych czynnościach należy nacisnąć "Zapisz", nazwać bazę danych i potem w oknie, które pojawiło się na początku należy wybrać ponownie "Tabela" i poniżej znajdować się będzie zapisana baza danych.
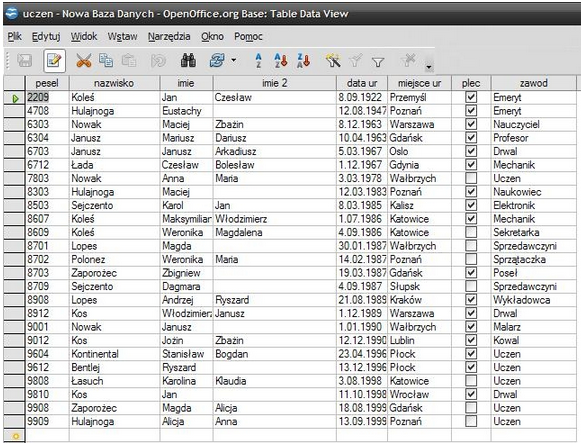
Przykładowa baza danych
Co to jest kwerenda?
Zapytanie (niekiedy zwane kwerendą, z łac. quaerenda) – czynność polegająca na zbieraniu lub poszukiwaniu informacji w aktach, bibliotekach, a przede wszystkim bazach danych.
Użytkownik serwera baz danych (program lub osoba) wysyła do niego zapytanie, na które serwer odpowiada przesyłając oczekiwane dane, czyli wynik zapytania. Zapytania mogą mieć na celu wyłącznie pobranie danych (tzw. zapytania wybierające), jak i usuwanie, dodawanie czy modyfikację danych (tzw. zapytania funkcjonalne).